Contents
Categories
By Patrick Comer
“Sample” is a simple word that is intrinsic to all the moving parts that are involved in research. The truth is, sample is not so simple. Rather, it is the result of many complex factors such as surveys, audience, respondents, platforms, incidence rate, length of interview, and time. And these same components also determine the cost of sample.
So, what specifically impacts sample cost? It all starts with you and your surveys. Since the beginning of survey time, we have largely based sample pricing priced on required audience – as indicated by incidence rate (IR) and length of interview (LOI). In other words, difficult-to-find audiences and longer surveys cost more, while easier-to-find audiences and shorter surveys cost less. In a manual world, it was challenging (if not impossible) to evaluate all of these simultaneously-competing factors in real-time, all the time. So we, suppliers and buyers, accepted an uneasy truce and settled on a “good-ish” proxy: IR + LOI = price.
Through programmatic sampling, we have learned that each survey – and, more specifically, each survey and buyer combination – carries a unique digital fingerprint containing its DNA for all to read. This digital fingerprint contains what we at Lucid lovingly refer to as a “survey’s health metrics.” We also expose this information to suppliers via API. And guess what? Suppliers voraciously consume this information, which informs decisions across all survey inventory. All of this takes place in real-time, all the time.
And guess what else? No programmatic supplier really prices on IR + LOI. So, when buyers focus on pricing sample (instead of individual surveys), they act under a false assumption and fail to optimize their individual buying power. Ultimately, this drives up the sample costs and decreases delivery rates.
Here’s why.
Every survey is a special snowflake.
We all know that there are many other factors besides LOI and IR that can drive price and delivery. Some are respondent-related: country, ethnicity, age, gender, and an infinite list of other audience target options. Some are survey-related: survey design, mobile optimization, survey platform, PII collection, and the list goes on.
The simple reality is that NO ONE knows how a survey is actually going to perform until it’s in-field. And we are not always accurate at predicting survey performance.
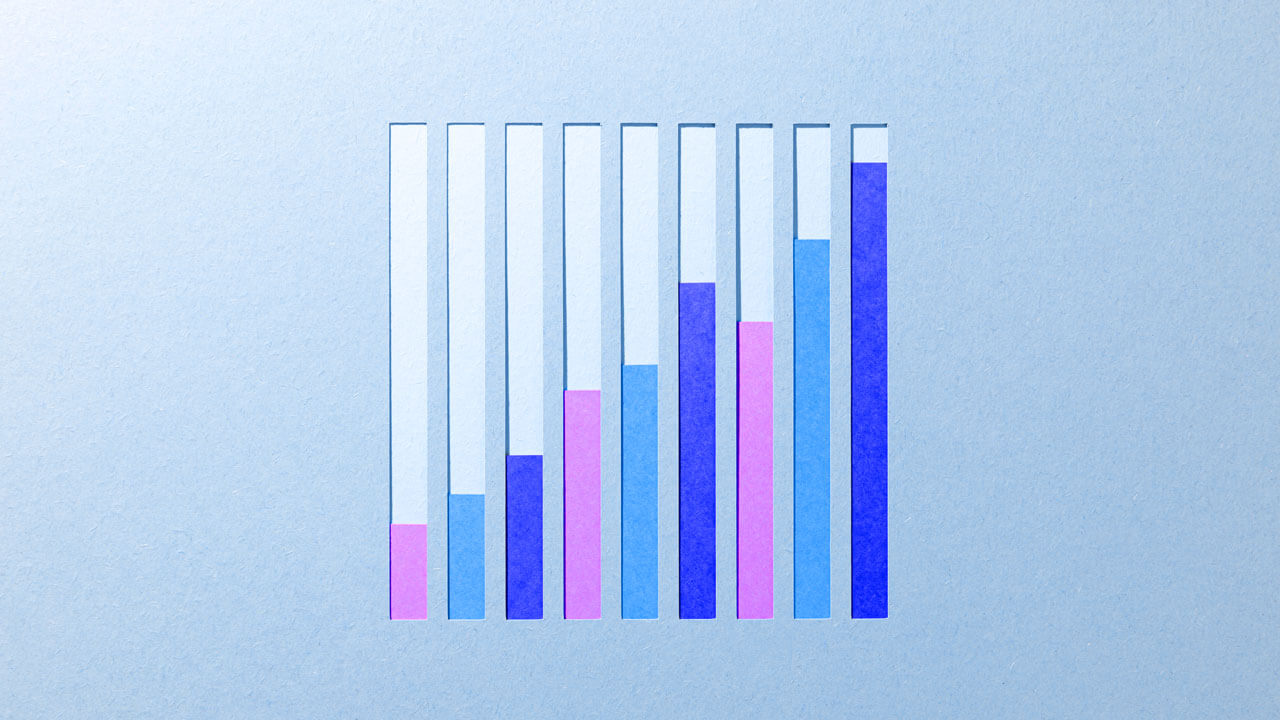
To demonstrate, we pulled 100 random surveys, all with a BID IR of 30%. After 24 hours, the ACTUAL IR ranged from 6% to 75% with an average of 23.3%. Rebasing them all to their day 1 ACTUAL IR, we can see how they changed each day.
Conclusion: only 10% of surveys that go into field are accurately projected at the BID state on both an LOI and IR basis.
No survey is an island.
Buyers and suppliers have vastly different perspective when it comes to surveys.
Every survey ever designed was done so in a vacuum. Each is precious to the researcher, the company, and the customer. For good reason, they believe the sun revolves around that survey. The buyer’s book of business is seen in the same light. Whether the buyer consumes $100K or $10M in sample a year, each believes their book of business is the most important and the suppliers will focus all their attention on it. Right?
In fact, suppliers have numerous opportunities for their respondents beyond a buyer’s single survey. First, there could be multiple individual surveys that a supplier has already bid on. Second, exchanges have thousands of surveys available to review. And finally, suppliers can use flat-rate platforms to push traffic to. Point being, suppliers have options not only when it comes to choosing a survey, but also the delivery mechanism.
There is no guarantee from the supplier to deliver a complete.
Rate cards are not a commitment from a supplier to deliver any number of completes to a survey; it’s simply a commitment to a price “if” they send a complete that fits into a definition of LOI and IR that the buyer creates. This means that if a survey is a terrible opportunity for the supplier and their respondents, they just stop sending sample.
Programmatic survey ranking is what’s really going on.
Sample suppliers are ranking every survey, every quota, every rate card, and every single opportunity across all platforms they have access to in real-time – recall the digital survey fingerprint we discussed earlier? They have complex, sometimes machine-learning algorithms that judge the relative value of each survey. If your survey falls down in ranking, guess what? You don’t get sample.
And here’s the kicker: they aren’t ranking your survey on IR and LOI.
Simply put, the only time your rate-card-driven survey gets more traffic is when it’s overpriced – meaning you’re willing to pay more than all the other buyers.
Conversion rate also determines the value of earnings per click (EPC).
Most survey ranking uses a version of EPC to determine the relative value of all surveys. A myriad of other variables are in the mix and each one is weighted based on the special sauce of the supplier. But, at the core, the math is simple: earnings (i.e. CPIs) / respondent sessions. In order to calculate this, you need to understand the conversion rate (i.e. the number of respondents that the supplier sends that actually complete the survey).
Let’s take three surveys:
Buyer A: 5 min LOI, $1.00 CPI, 20% Incidence
Buyer B: 10 min LOI, $5.00 CPI, 10% Incidence
Buyer C: 25 min LOI, $10.00 CPI, 2% Incidence
Which one is more valuable?
Well, we can’t know for sure, unless we understand the conversion rate, which is correlated to incidence rate – but only loosely – and the correlation is highly dependent on how the buyer defines incidence. For the purposes of this example, we will assume that incidence = conversion rate.
Buyer A has a $.20 EPC (CPI * Conversion)
Buyer B has a $.50 EPC – Round 1 winner!
Buyer C has a $.20 EPC
What happens if the supplier values the time of the respondent and divides through by minutes?
Buyer A has a $.04 Earnings Per Minute (EPM = EPC / LOI)
Buyer B has a $.05 EPM – Round 2 winner!
Buyer C has a $.008 EPM
Finally, each buyer has a Reconciliation Rate history. Meaning, each buyer typically rejects a certain amount of sample for each survey for data quality. The CPI that a buyer is offering is actually projected to be worth an amount less, based on their reconciliation history. Simply put, if you normally reject 20% of data, then a $5.00 CPI is only worth $4.00 to the supplier over the long term. Yes, your data cleaning impacts your survey ranking and, therefore, price.
Let’s assume the following Reconciliation Rates
Buyer A (10%)
Buyer B (40%)
Buyer C (5%)
Then the projected Earnings per Minute are:
Buyer A Survey = $.036 Project EPM – Round 3 winner and CHAMPION!
Buyer B Survey = $.03
Buyer C Survey = $.0076
Here’s the fundamental problem: the buyer is completely out of step with the actual value of the surveys they are launching, which leads to a myriad of pricing and delivery challenges.
The answer? Convert to a floating price.
Because each survey is unique, and its value is virtually unknown before launch, pricing needs to be dynamic.
Once the survey goes into field, both the buyer and supplier can continually project its relative value based upon actual performance. In other words, surveys that perform well can be updated in real-time to clear at a lower CPI (which saves money) and surveys that are harder than anticipated can be updated with a higher price to attract more supply. The most sophisticated buyers are now matching the suppliers on ranking their opportunities and adjust pricing on the fly. Not only does programmatic buying mean the automation of fielding process, but also real-time pricing by the buyer and seller.
What does this mean, ladies and gentlemen? Ultimately, this all serves to better sustain and grow the long-term health of our research ecosystem. Proper pricing for proper audience equals long-term sustainability. As we are seeing, it also means that it becomes more, not less, feasible to find those difficult audiences you are looking for.
We’ve seen buyers adopt a variety of modern strategies. Our most sophisticated partners use our APIs to automate per-interview pricing based on the conditions of their survey, their time-in-field, and their budget. Others, including our own services team, give project managers training and discretion to fill a project efficiently based on the throughput of the exchange. If you’ve already built your sample procurement around rate cards, don’t worry. We have a solution for you.